
Técnicas de preprocesamiento de datos
El preprocesamiento de datos es un paso crucial en el proceso de análisis de datos que consiste en preparar y limpiar los datos antes de analizarlos o utilizarlos para entrenar modelos de aprendizaje automático. El objetivo principal del preprocesamiento de datos es transformar los datos brutos (sin valor) en un formato que sea más fácil de comprender y analizar tanto por humanos como por máquinas y que realmente aporte valor a la organización.
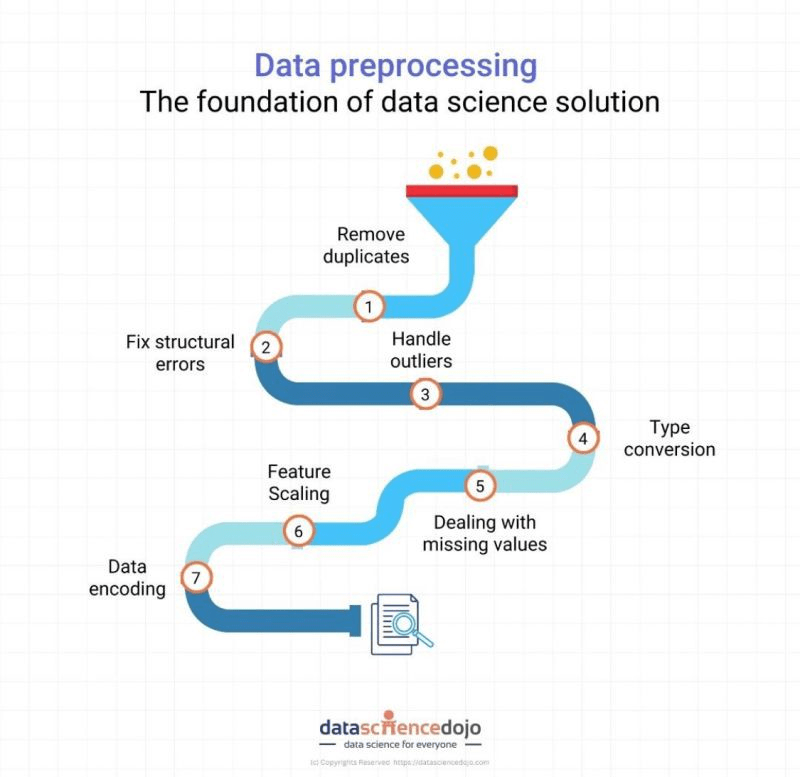
Las técnicas de preprocesamiento de datos se utilizan para resolver problemas comunes de calidad de los datos, como valores que faltan, formatos de datos incoherentes, valores atípicos, así como para transformar los datos en un formato más útil para el análisis. Estas técnicas son esenciales para garantizar que el análisis resultante sea preciso y fiable.
Puede ser utilizado por una amplia gama de profesionales en diversas industrias, incluyendo analistas de datos, científicos de datos, ingenieros de aprendizaje automático y analistas de negocio. Desde el punto de vista de las aplicaciones, se utiliza en diversas aplicaciones, como el modelado predictivo, la clasificación, la agrupación y el análisis de texto.
Existen varios tipos de técnicas de preprocesamiento de datos, como la limpieza de datos, la normalización de datos, la codificación de datos, la selección de características, la extracción de características, la integración de datos y la reducción de datos.
La elección de las técnicas dependerá de las características específicas del conjunto de datos y de los objetivos del análisis. En general, el preprocesamiento de datos es un paso esencial en el proceso de análisis de datos que permite extraer información precisa y fiable de datos complejos:
1 Depuración de datos: La limpieza de datos es un primer paso importante en el preprocesamiento de datos. Consiste en identificar y corregir cualquier error en los datos, como valores que faltan, duplicados o datos incoherentes. La limpieza de datos puede llevar mucho tiempo, pero es esencial para garantizar la exactitud y fiabilidad de los datos.
2 Normalización de datos: La normalización de datos consiste en escalar los valores del conjunto de datos para que se encuentren dentro de un rango específico. Esto se suele hacer para eliminar los efectos de las diferentes unidades de medida y hacer que los datos sean más comparables. Entre las técnicas de normalización más comunes se encuentran el escalado mín-máx y la normalización z-score.
3 Codificación de datos: La codificación de datos es el proceso de convertir datos categóricos en forma numérica para que puedan utilizarse en algoritmos de aprendizaje automático. Esto es necesario porque muchos algoritmos de aprendizaje automático requieren datos numéricos como entrada. Entre las técnicas de codificación más comunes se encuentran la codificación de etiquetas y la codificación de un solo punto.
4 Selección de características: La selección de características consiste en seleccionar las características o variables más importantes del conjunto de datos que se utilizarán para entrenar el modelo de aprendizaje automático. Esto se hace para reducir la complejidad del modelo y mejorar su precisión. Entre las técnicas habituales de selección de características se incluyen el análisis de correlación, la información mutua y el análisis de componentes principales.
5 Extracción de características: La extracción de características consiste en transformar los datos brutos en un formato más útil e informativo. Suele hacerse para reducir la dimensionalidad del conjunto de datos o extraer características relevantes que puedan utilizarse para entrenar el modelo de aprendizaje automático. Entre las técnicas habituales de extracción de características se incluyen el análisis de componentes principales, la descomposición de valores singulares y el análisis de componentes independientes.
6 Integración de datos: La integración de datos consiste en combinar datos de múltiples fuentes en un único conjunto de datos para su análisis. Esto suele ser necesario cuando se trabaja con grandes conjuntos de datos repartidos en varias tablas o bases de datos. Entre las técnicas habituales de integración de datos se incluyen las operaciones de unión y fusión de datos.
7 Reducción de datos: La reducción de datos consiste en reducir el tamaño del conjunto de datos conservando toda la información útil posible. Suele hacerse para mejorar la eficacia y la velocidad del modelo de aprendizaje automático. Entre las técnicas habituales de reducción de datos se incluyen el muestreo, la agrupación y la selección de características.
En general, estos 7 tipos de técnicas de preprocesamiento de datos son esenciales para preparar los datos para el análisis y construir modelos de aprendizaje automático precisos. La elección de las técnicas utilizadas dependerá de las características específicas del conjunto de datos y de los objetivos del análisis.
Puedes encontrar la versión en inglés de este articulo en Medium
Si te interesan más articulos sobre este tema, no te olvides volver con regularidad a nuestro blog.





 como cientista de datos / Data Scientist")