
[ad_1]
Lo primero de todo…
Por mucho que se comenten como las tecnologías mas punteras, en realidad, nada de más lejano. Todas estas tecnologías de análisis de datos llevan decenas de años, y han ido evolucionando con una velocidad directamente proporcional a la capacidad de transmitir y procesar datos. La gran mayoría de las analíticas de datos están apoyados sobre métodos matemáticos, álgebra, estadística, etc…. que en algunos casos tienen mas algunos siglos de historia.
La proprio espirito de lo que es un cientifico de datos podría remontar unos 3 siglos a tras a una Londres todavía casi medieval, con una epidemia que estaba provocando la muerte de muchos londinenses, y cuya medicina de la época no conseguía encontrar una solución, hasta que un alguien se le ocurrió coger todos los datos de localización de la enfermedad y contrastarlo con mapas de otra características como por ejemplo el hidrográfico, e llegar a la conclusión que había una conexión entre enfermedad y pozos de aguas.
La única diferencia entre entonces y hoy, es que la digitalización de la economía ha permitido la existencia de datos prácticamente ilimitados que pueden ser intercambiados, distribuidos y procesados a una velocidad todavía no infinita.
Incluso con la evolución del poder de computación a la luz de la Ley de Moore, no fue hasta que cambios de modelos de computación generados por las nuevas empresas puntocom como Google, Twitter, Facebook y otras que realmente no se ha dispuesto de una capacidad realmente relevante de procesar los datos de una forma elevada.
Con estas dos visiones tenemos una primera aproximación de las diferencias:
– Encontrar respuestas a preguntas
– Encontrar formas de procesar los datos
Los científicos de datos, están para buscar las respuestas a las preguntas que le rodean. Estas preguntas pueden ser de muchos y diferentes tipos, pueden relacionadas con rentabilidad de negocios o inversiones, optimizaciones de producción, encontrar la cura del cáncer, saber lo que piensan nuestros usuarios, saber que van a comprar en el futuro nuestros consumidores, etc… Es fácil ver que dentro de las preguntas con vista al pasado, al presente y al futuro, dado que son realidades que se mezclan frecuentemente en el trabajo de un data scientist, porque para imaginar el futuro es necesario saber como se ha comportado el pasado, validarlo con el presente y finalmente proyectarse a ese futuro posible.

Algo que es importante también tener en cuenta, es que la función dentro de los datos, depende mucho de la dimensión de la empresa, no es lo mismo ser un científico de datos en una pequeña suportar sin fondos para la contratación de equipos grandes, con una grande multinacional con muchos recursos y en que probablemente contara con equipos dedicados para cada función asociada al proceso de colectar,tratar y analizar los datos. Por lo lo mas probable es que en una empresa pequeña tanto un data scientist como un ingeniero de datos harán funciones muy parecidas, mientras que en las grandes empresas, su especializaran a muy bajo nivel.
Para realizar estas operaciones, son necesarios muchos datos, de muchos tipos, de muchas diferentes orígenes y con requisitos muy diferentes de proceso antes de que pueda ser utilizado en su análisis. Con estas tareas se preocupan los ingenieros de datos o arquitectos de big data, o muchos otros nombres.
Son los que son capaces de diseñar, montar y mantener todos los sistemas necesarios para conseguir encontrar los datos necesarios, recolectarlos en los sistemas donde se llevará a cabo su proceso, y garantizar que habrá la capacidad de computación suficiente como para que conseguirlo no lleve una eternidad, si no más bien sean realizada en el tiempo mas competitivo posible de tal forma que sumado a la labor del cientifico de datos, podamos conseguir ver la realidad de la temática que nos interesa antes de los demás.
Estos dos funciones no son exclusivas y complementarias entre si, y tienen muchos puntos en común, pero en el día a día, la principal diferencia estará en el enfoque mental que cualquier uno de ellos tiene sobre los datos y su utilización.
si comparásemos los dos roles a dos conductores que quieren ir de Madrid a Pamplona, el cientifico de datos miraría el GPS para intentar visualizar los posibles problemas del camino, mientras que el ingeniero de datos, miraría las características del trayecto como velocidades, tiempos de llegada, etc.. Claro que por lo menos ellos llevarían GPS y por lo cuanto pueden adaptarse con tiempo a lo que ocurre por delante de si. Una empresa sin datos, es como viajar sin GPS y estar al merced de lo que ocurre.
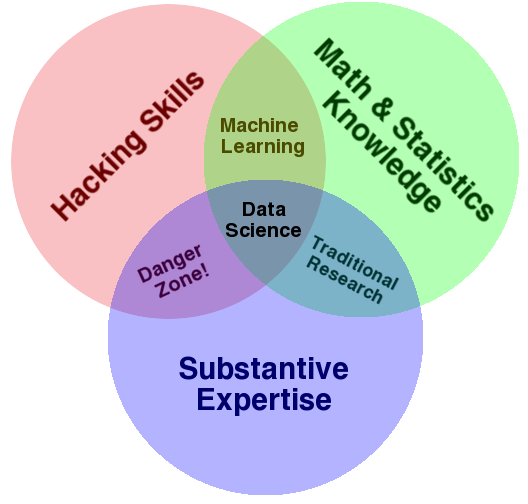
Diagrama de Venn del «Científico de datos» (Fuente: Drew Conway)
Científico de datos
- Enfoque en las preguntas utilizando los datos y su relación para estructurar hipótesis que pueden ser probados con la utilización de los modelos de análisis creados.
- Ser capaz de contar historias con base en las análisis realizadas. el 80% del éxito es saber contar los resultados obtenidos.
- Conocimiento especializado sobre el área de análisis
- Conocimiento formal sobre matemáticas, álgebra, estadísticas, métodos numéricos, algoritmos
- Conocimiento de programación y herramientas de proceso y análisis de datos.
Arquitecto o ingeniero de datos
- Enfoque sobre la disponibilidad de los datos, su recolección, su almacenamiento
- Enfoque sobre las arquitecturas de comunicación y computación
- Enfoque sobre las herramientas de adquisición, proceso y almacenamiento de los datos.
- Algún enfoque sobre el análisis
¿Como operan?
Lo primero de todo, el análisis de datos nunca debería empezar desde abajo de un departamento de tecnología y subir en dirección de la empresa. El enfoque debe ser desde las necesidades competitivas e estratégicas de la dirección, que sugieren preguntas de difícil solución, y que necesitan de diferentes fuentes y volúmenes de datos para permitir crear unos modelos capaces de simular la realidad e imaginar las posibles respuestas.
Empezar desde arriba va a dar la posibilidad de entender lo que se quiere hacer y que tiene la empresa para poder realizarlo, y en el caso de que no disponga de las posibilidades para hacerlo, entonces buscar especialistas o tecnologías para su implementación.
Empezar al revés, con una necesidad tecnológica es generalmente condenado a terminar con una solución propietaria cara y aislada, que tendrá a la organización rehén de la misma durante mucho tiempo.
Una vez, que la dirección de la organización tiene una idea clara de los retos existentes y de las preguntas a que debe enfrentarse para conseguir darle una respuesta, es cuando debe buscarse con la ayuda de un data scientist cual son las posibilidades que existen dentro o fuera de la organización para poder hacerlo. Hay muchas ocasiones en que no hay ni datos ni tecnologías disponibles y que por lo cuanto la vía debe ser de empezar a cambiar los modelos de operación para generar los datos que se necesite.
¿Que formación?
Que deben estudiar y cuales los perfiles más idóneos para poder estudiar, y una pregunta interesante, es necesario formación universitario complementaria de máster?
De forma general, el tipo de conocimiento de matematicas/estadisticas van a estar más fuertes en personas que hayan cursado formación de economia, matematicas, fisicas, estadisticas, quimica, geografia, etc… Están habituados a los datos como motor de inferencia de otras realidades y se les dá bien la abstracción que es necesaria tener para poder ver lo que los datos ocultan. Generalmente estos perfiles tienen cierta capacidad lógica por lo que poder llegar a tener una visión de alto nivel sobre programación no es demasiado complicado.
El tema de sistemas, comunicaciones y arquitecturas de computación les es más complicado entender, por lo que estarán generalmente mejor enfocados en programas de Data Science.
Por otro lado, ingenieros, informáticos y otras formaciones más técnicas estarán mejor enfocados en programas de Big Data donde tendrán más facilidades para entender la complejidad de los sistemas y sus interdependencias, algo que resulta mucho más complicado a los anteriores, y por lo cuanto un programa de Big Data les dará mejor provecho.
Estas divisiones no son atómicas y hay muchos ingenieros que son muy buenos con la relación de los datos, y vice versa.
Es necesario un máster o un programa universitario para poder formarse? La respuesta es complicada y depende de cada persona. Los principios formales y tecnológicos subyacentes a estas disciplinas se pueden aprender fácilmente con auto estudio, aplicarlos de forma correcta es más complejo, porque es necesario la capacidad de entender las especificidades del problema que se quiere responder, y es necesario la existencia de una dialogo constante que permita ir avanzando en el conocimiento del mismo para ir mejorando de forma gradual la concepción y abstracción de mismo. Sin esta relación real, es como intentar aprender a dibujar o programar sin hacer dibujos o sin programa. Se puede llegar a entender, pero no se conseguirá nunca saber aplicarlos.
Referencias
[ad_2]











